CAT | Tools
31
Build and publish your own PHP Mongo packages
0 Comments | Posted by Žilvinas Šaltys in PHP, Tools
I had a problem at work where we were using a php mongo driver version 1.3.7 which was crashing for us due to a bug in the driver. Since then they have released a new version of the driver 1.4.0 which solves the previous issue but introduces a new one. Fortunately it was quickly fixed on github but not yet released on pecl. I wanted to try the latest driver to see if it works but did not want to custom compile it and instead wanted to use pecl.
This is when I found a howto create a pear repository on github. Following these instructions I set up my own pear repository. Then I simply checked out the php mongo driver, changed the package.xml to point to my channel and ran pear package which gave me a php mongo driver package which I could now add to my own pear github repo using pirum.
Now I can use this repo to install my own packages for testing, share it with others or even use it in production if I can’t wait for the official release.
Sometimes it’s useful to be able to quickly peek what keys memcache is storing and how old are they. A good use case for example could be to check whether something is cached or not or that they expire as they should.
At first I found a way to dump memcache keys through telnet. However if a memcache instance is fairly large and has a lot of slabs and thousands of keys it becomes impractical to do it manually.
I wrote a simple utility that helps me find keys across all memcache slabs.
#!/usr/bin/php
< ?php
$host = "127.0.0.1";
$port = 11211;
$lookupKey = "";
$limit = 10000;
$time = time();
foreach ($argv as $key => $arg) {
switch ($arg) {
case '-h':
$host = $argv[$key + 1];
break;
case '-p':
$port = $argv[$key + 1];
break;
case '-s':
$lookupKey = $argv[$key + 1];
break;
case '-l':
$limit = $argv[$key + 1];
}
}
$memcache = memcache_connect($host, $port);
$list = array();
$allSlabs = $memcache->getExtendedStats('slabs');
$items = $memcache->getExtendedStats('items');
foreach ($allSlabs as $server => $slabs) {
foreach ($slabs as $slabId => $slabMeta) {
if (!is_numeric($slabId)) {
continue;
}
$cdump = $memcache->getExtendedStats('cachedump', (int)$slabId, $limit);
foreach ($cdump as $server => $entries) {
if (!$entries) {
continue;
}
foreach($entries as $eName => $eData) {
$list[$eName] = array(
'key' => $eName,
'slabId' => $slabId,
'size' => $eData[0],
'age' => $eData[1]
);
}
}
}
}
ksort($list);
if (!empty($lookupKey)) {
echo "Searching for keys that contain: '{$lookupKey}'\n";
foreach ($list as $row) {
if (strpos($row['key'], $lookupKey) !== FALSE) {
echo "Key: {$row['key']}, size: {$row['size']}b, age: ", ($time - $row['age']), "s, slab id: {$row['slabId']}\n";
}
}
} else {
echo "Printing out all keys\n";
foreach ($list as $row) {
echo "Key: {$row['key']}, size: {$row['size']}b, age: ", ($time - $row['age']), "s, slab id: {$row['slabId']}\n";
}
}
This script accepts 4 parameters:
-h host
-p port
-s partial search string
-l a limit of how many keys to dump from a single slab (default 10,000)
The easiest way to use it:
./membrowser.php -s uk
Searching for keys that contain: ‘uk’
Key: 1_uk_xml, size: 3178b, age: 1728s, slab id: 17
Key: 2_uk_xml, size: 3178b, age: 1725s, slab id: 17
Key: 3_uk_xml, size: 3178b, age: 1721s, slab id: 17
Download memcache keys dump script.
P.S some of the code I’ve copied from 100days.de blog post.
30
PyDumpy - Partial sorted MySQL database dumps
0 Comments | Posted by Žilvinas Šaltys in MySQL, Tools
is a simple Python utility that might be helpful for developers struggling to get fast and partial database snapshots from production databases. It does it’s job by checking the database information schema to find out the approximate rows count available in each table and limits the table if needed to avoid dumping too much data as some databases may have hundreds of gigabytes of data. It then passes all the limits information it gathers to mysqldump a tool created by MySQL to do the actual dumping.
Python does not have a built in package to connect to MySQL as for example PHP does and therefore PyDumpy relies on MySQL for Python package to work. PyDumpy also relies on mysqladmin to do the actual dumping.
PyDumpy is very simple to use. For example to dump a maximum of 50 000 rows from each table type:
./pydumpy.py -H host -u user -p pass -n dbname -limit=50000
PyDumpy also allows to specify row limits and sorting preferences for each table specifically:
./pydumpy.py -H host -u user -p pass -n dbname -limit=50000 -ask-to-limit -ask-to-sort
If you find this tool useful please feel free to provide feedback by leaving a comment.
A while ago I blogged about an XML Beautifier Tool which is able to tokenize an XML string and output it in human readable format. Strangely enough I noticed that I get quite a few pageviews from people searching for such a tool. Though this tool may be useful to a lot of people I think it is flawed and has serious issues with formatting, speed and memory consumption.
This inspired me to write a new version of XML formatter. It’s based on a SAX parser which is kind of “ugly” to implement and build around but because of it’s event based nature it’s super fast and has a very low memory footprint. The new version of the formatter shouldn’t peak higher in memory than 200 - 300kb even when the XML files start to weight over a megabyte. It also should not have any problems with indentation because it no longer tries to tokenize the XML itself and uses libxml to do the job. I also tried to make the tool documented and extendable.
It’s usage is really simple. All you have to do is initialize an object of XML_Formatter by passing an xml input stream, xml output stream and an array of options and call the format method. You might wonder why it requests input and output streams instead of a file name or a string. It does that to avoid high memory consumption. Here’s an example of how one might use XML_Formatter:
require('XMLFormatter.php');
$input = fopen("input.xml", "r");
$output = fopen("output.xml", "w+");
try {
$formatter = new XML_Formatter($input, $output);
$formatter->format();
echo "Success!";
} catch (Exception $e) {
echo $e->getMessage(), "\n";
}
Nevertheless this tool is quite powerful in what it can do (I was able to format other website’s XHTML or tidied HTML sources) it also has some problems which are not actually related to the formatter but may seem odd to the user. The PHP xml parser does not understand such entities as or unsescaped ampersands like in ?x=1&y=1. So it’s the user’s responsibility to provide “correct” XMLs to the formatter.
Other than that I hope it will prove useful to someone. Download the latest version of the XML_Formatter.
26
Building Drizzle on Cygwin or getting as far as possible
0 Comments | Posted by Žilvinas Šaltys in MySQL, Tools
It’s been quite a while i have this sort of desire to offer my help for some opensource project i like. One of my most favorite candidates is Drizzle. I should say my knowledge of C is really poor and there’s a whole crazy world out there full of C applications and build tools.
Nevertheless i decided to atleast try and see if i would be able to build it and maybe change something, run some tests. As I am a Windows user i found out the only way for me to build Drizzle is through Cygwin. I started with installing the latest stable version of Cygwin 1.5.25-15. I must say that their installer is really nice but i would offer to add a package search feature. Might help when you want to install numerous packages.
So what’s next? I found this wiki page about building drizzle and figured first thing i should do is get Bazaar. I installed the following packages using Cygwin installer:
- bison
- bzr
- gettext
- readline
- libpcre0
- pcre
- pcre-devel
- libtoolize
- gperf
- e2fsprogs
And then went on to get the Drizzle sources:
mkdir ~/bzrwork
bzr init-repo ~/bzrwork
cd ~/bzrwork
bzr branch lp:drizzle
Now onto building. Here’s where all the fun begins.
Drizzle requires a tool named libevent which is not available through Cygwin installer and you must build it yourself. And still you can’t build libevent with the latest version of Cygwin because it lacks certain functionality. After some googling i found a patched IPV6 version of Cygwin that fixes these issues. Added the #define EAI_SYSTEM 11 to http.c and finally were able to ./configure && make && make install libevent.
You also need protobuf installed. And there’s no package for that either. Actually this protobuf is quite nice stuff. Protocol Buffers are a way of encoding structured data in an efficient yet extensible format. Google uses Protocol Buffers for almost all of its internal RPC protocols and file formats.
Now that we seem to have all the packages installed we can start building drizzle. It should be as easy as this:
cd drizzle
./config/autorun.sh
./configure
make
make install
It is not. First to be able to compile Drizzle you need to have gcc4. And even if you do, ./configure must need to know where it is. So we need to use additional flags CC and CXX. Then you need to show ./configure where libevent is installed by adding a flag -with-libevent-prefix=/usr/local or any other place you have it in. I also found a really ugly problem with warnings. I wasn’t able to compile drizzle because it stopped somwhere in gnulib complaining about some warnings that were treated as errors. Funny enough there is a sarcastic option to disable these warnings: -disable-pedantic-warnings. You also probably want to install Drizzle somwhere else than usual by using: -prefix=/some/deploy/dir.
In the end you come up with something like this:
./configure CC=gcc-4 CXX=g++-4 -with-libevent-prefix=/usr/local -disable-pedantic-warnings -prefix=/some/deploy/dir
That’s how far i’ve got with it. Though i’m still not able to compile it. I get an error somwhere in mystrings library that is related to some datatype casting issues. Hopefully i’ll be able to hack through this ![]()
9
Using pre commit hooks to integrate SVN with project management tools
0 Comments | Posted by Žilvinas Šaltys in Tools
Most developer teams work with version control tools like SVN or Git. Most of those teams use certain project management tools like Basecamp or Fogbugz in our case.
We came up with an idea to require developers to write down SVN revision numbers in commit messages. This helps to relate code changes to actual tasks if such a need arises. To do that we’ve created a pre commit hook that requires developers to insert internal project management tool task number to the SVN commit comment field.
A pre commit hook can be a simple bash script. In our case it was this script:
#!/bin/sh
REPOS="$1"
TXN="$2
# Make sure that the log message contains some text.
SVNLOOK=/usr/bin/svnlook
$SVNLOOK info -t "$TXN" "$REPOS" | grep -P 'FB:\s*\d{3,6}' > /dev/null
if [ $? -ne 0 ]; then
echo -e "FogBugz case number is missing in the comment.\n" 1>&2
echo -e "Please add text 'FB: CASE_NUMBER' to your comment." 1>&2
exit 1
fi
exit 0
I have been a user of FireBug for quite a long time and it saved me a lot of hours of pain debugging AJAX applications. When I see developers trying to figure out why their AJAX applications are not working without using FireBug it sometimes looks like an inexperienced woman trying to park a car without any luck whatsoever.
And then recently i found FirePHP while reading php|architect and it seems to me a such a nice tool it’s well worth to blog about it. If you want to debug ajax applications with FireBug you must do your own variable dumps which break the output. While FirePHP is capable of sending all this data through http headers without breaking the response of your json, xml, image responses. It also provides a very nice library for logging various stuff.
One of the things I really liked is the ability to easily view backtraces through FirePHP. Though it seems to me it can only view backtraces of your own defined local php function calls. It would be nice to see FirePHP integrated with Xdebug. Then it could do a full stack trace with all the parameters involved and even memory usage.
I also love the fact that there is a Zend_Log_Writer for Firebug. It also can send information to firebug console. But it’s not as “sweet & cute” like FirePHP.
I believe that FireBug, FirePHP, Xdebug are the must have tools for every php web developer. It saves more than a reasonable amount of time spent debugging.
We’re using FogBugz 6 for our daily project management needs. It’s a great tool in many ways and I think it will get only better on the way. But FogBugz lacks one quite important feature. There is no way to easily get a report how much time each of your developers spent on their tasks during the day or to see on what are they currently working. You might wonder why is that.
Well it’s quite funny but the company behind FogBugz doesn’t really want to provide this kind of functionality. Because they believe this would make people provide bad estimate data to FogBugz. You can read more about it on Joel on Software blog post about amnesia. They might be true about the bad data thing. But in my opinion they aren’t the ones who should decide how people should to use their tools. If people want to shoot themselves in foot - explain to them that it’s wrong and what will happen if they won’t listen and then let them shoot themselves in the foot.
We for example need to know on what tasks our developers were working during the day and what are they doing at any moment of time. And ofcourse seeing that a certain task took too long or that a developer was doing something without a task for 4 hours is very valuable. In other words if people know for what reason this tracking data is gathered they might as well not lie and provide good data. Don’t force your developers to have 8 hours long reports. You should know they spend atleast 2 hours doing whatever they like.
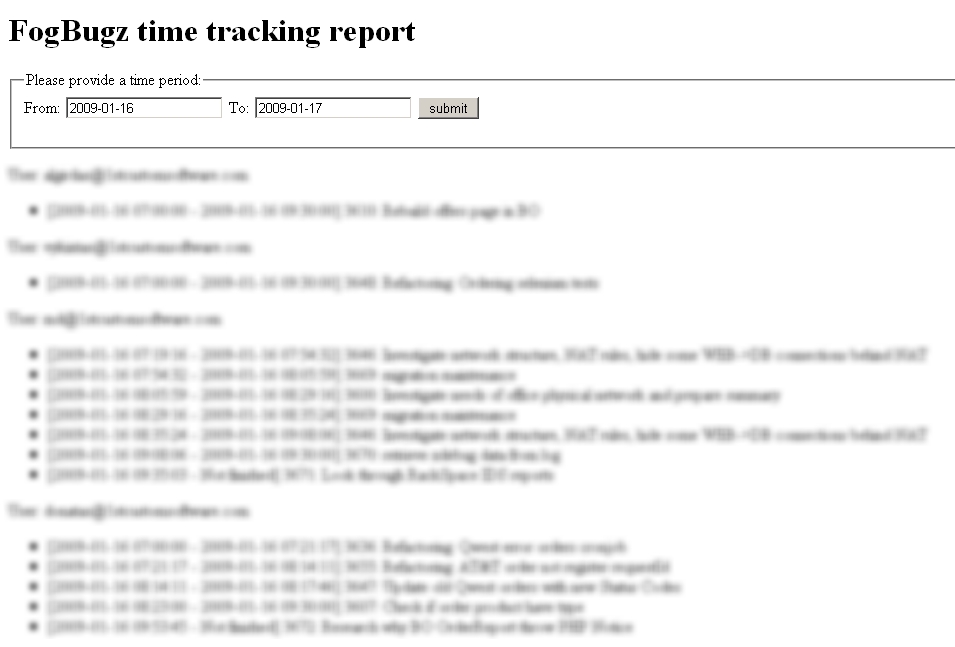
I tried to look for 3rd party solutions that would in some way allow us to have time tracking reports, but I didn’t like any of them and of course they are all commercial solutions. I got really excited to find out that FogBugz has an API that allows to do various actions. One of those actions allows to get a user time sheet report for a certain time interval. So I quickly developed a small php application that would login to the system with all the users we have and aggregate their time sheets. The application itself is no piece of art but I think it’s simple and it gets the basic job done. You are welcome to try y fogbugz time tracking application out yourself. It has a dependency to ZendFramework’s HTTP client. You can easily replace it with anything you like. To install the application you need to configure the index.php by providing the api url, fogbugz users list, current timezone, and path to the zend framework. If you have any problems or requests please feel free to contact me.
I’m also adding a screenshot if you care how the reports look:
I’m a subscriber to a PHP magazine php|architect. I still haven’t finished reading the july edition. In the past I didn’t have to do much with web applications and mobile phones. Recently though we had to make a certain part of a bigger application we made to be available on blackberry. The problem of course we faced is of course how to identify if the current agent is a mobile phone. And that’s how we found WURFL.WURFL aka Wireless Universal Resource File is a device description repository or to make it simple it’s a big library of various mobile phones abilities and attributes mapped to user agents.
What does this have to do with php|architect? Well in the 2008 july edition of php|architect there is a really lovely article about web application tools for mobile phones. I found there are two more PHP tools that a mobile web applications developer should know of. It’s Tera-WURFL and HAWHAW. And again to make it simple Tera-WURFL is a mysql database for WURFL to make WURFL super fast and HAWHAW is a object oriented toolkit to create mobile web applications. Basicly with HAWHAW you can construct pages using objects and then HAWHAW renders them to apropriate formats such as WML, XHTML MP, XHTML using the data it gets from Tera-WURFL. According to the php architect article Wikipedia is using HAWHAW.
I don’t have to do much with mobile web applications I think it’s great that these kind of tools are available because I know it is easy to develop these kinds of applications if I or others have to.
In my previous blog post I wrote that me and my friend probably developed a first working google page rank check php implementation on linux. Seems I was wrong. Jan Bogutzki has an implementation on his functions-online.com website that also works on linux. He sent me his version of implementation and I must admit it looks cleaner and more simple than ours. You can download the copy he sent me if you are after a better approach.