TAG | free
We’re using FogBugz 6 for our daily project management needs. It’s a great tool in many ways and I think it will get only better on the way. But FogBugz lacks one quite important feature. There is no way to easily get a report how much time each of your developers spent on their tasks during the day or to see on what are they currently working. You might wonder why is that.
Well it’s quite funny but the company behind FogBugz doesn’t really want to provide this kind of functionality. Because they believe this would make people provide bad estimate data to FogBugz. You can read more about it on Joel on Software blog post about amnesia. They might be true about the bad data thing. But in my opinion they aren’t the ones who should decide how people should to use their tools. If people want to shoot themselves in foot - explain to them that it’s wrong and what will happen if they won’t listen and then let them shoot themselves in the foot.
We for example need to know on what tasks our developers were working during the day and what are they doing at any moment of time. And ofcourse seeing that a certain task took too long or that a developer was doing something without a task for 4 hours is very valuable. In other words if people know for what reason this tracking data is gathered they might as well not lie and provide good data. Don’t force your developers to have 8 hours long reports. You should know they spend atleast 2 hours doing whatever they like.
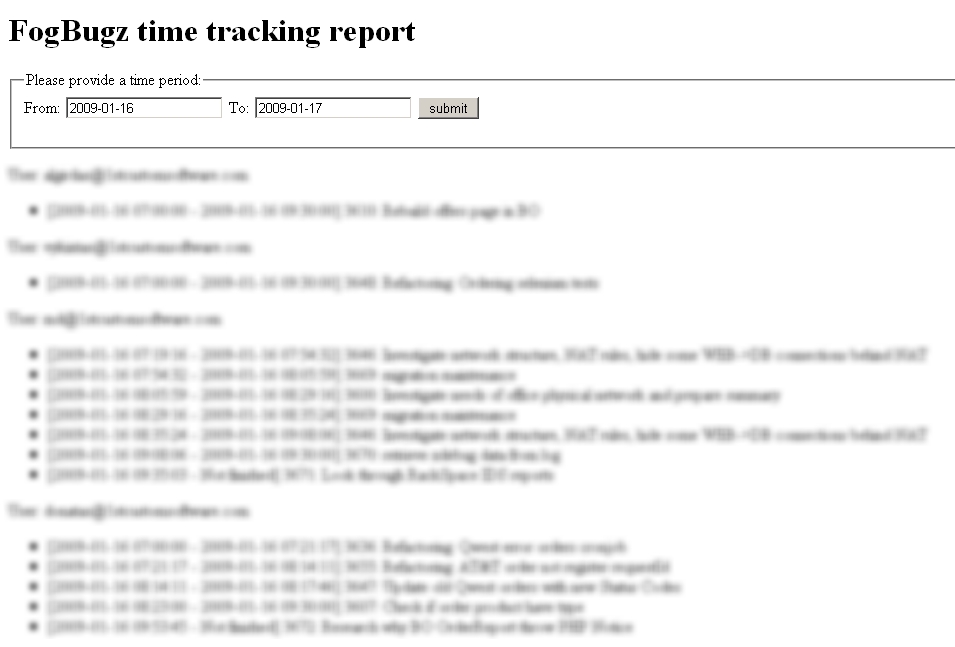
I tried to look for 3rd party solutions that would in some way allow us to have time tracking reports, but I didn’t like any of them and of course they are all commercial solutions. I got really excited to find out that FogBugz has an API that allows to do various actions. One of those actions allows to get a user time sheet report for a certain time interval. So I quickly developed a small php application that would login to the system with all the users we have and aggregate their time sheets. The application itself is no piece of art but I think it’s simple and it gets the basic job done. You are welcome to try y fogbugz time tracking application out yourself. It has a dependency to ZendFramework’s HTTP client. You can easily replace it with anything you like. To install the application you need to configure the index.php by providing the api url, fogbugz users list, current timezone, and path to the zend framework. If you have any problems or requests please feel free to contact me.
I’m also adding a screenshot if you care how the reports look:
In my previous blog post I wrote that me and my friend probably developed a first working google page rank check php implementation on linux. Seems I was wrong. Jan Bogutzki has an implementation on his functions-online.com website that also works on linux. He sent me his version of implementation and I must admit it looks cleaner and more simple than ours. You can download the copy he sent me if you are after a better approach.
If you found this blog post on while searching for a php google page rank class implementation that works on non windows machines then it is your lucky day! You found it! Congratulations!
To my knowledge this is the first available php google page rank retrieval implementation that works on any platform. We have spent hours searching for such a thing online but we couldn’t find it. There are some php google pagerank tools online, they all work, but they are all limited to windows machines.
Why is so you might ask? Well originally the google pagerank retrieval algorigthm is not public. But google made a browser plugin that was able to calculate the google pagerank for any website you visit. So some freaky geeks dissasembled that plugin and got their hands on the google page rank calculation implementation. Then this implementation was ported to various languages such as Javascript, PHP. The google page rank implementation is sort of protected by calculating a “unique” hash of the given URL. And here the MAGIC begins.
To calculate this hash the algorithm overflows 32bit integers on XOR operations. Aaaand.. 32bit XOR overflows work quite differently on windows and linux in PHP! If you overflow a 32bit integer on windows it just truncates the result to 32 left most bits and returns a new integer. SMART! And on linux XOR overflow just returns the MAX INTEGER value. What did we do? Oh.. We created a simple class to simulate windows 32bit XOR operations overflow using the PHP gmp extension. Tadam! We have also cleaned up the code, documented and made it look shiny ![]()
You can download and use it at your own will. I hope this will help you. If it did just leave a comment and say thanks because we are such nice guys to help you out ![]()
To use the class try:
require_once("GooglePageRank.php");
echo GooglePageRank::get("http://www.yahoo.com");
Happy Programmers Day!
p.s Google™ search engine and PageRank™ algorithm are the trademarks of Google Inc.
Update: PageRank class relies on the GMP extension which is not always enabled by default. On Linux Ubuntu it comes as a separate package php5-gmp.
9
Free multiple XHTML, HTML validator tool
0 Comments | Posted by Žilvinas Šaltys in (X)HTML, PHP, SEO, Tools, Web
If you’re working with SEO you want to make sure your website is XHTML valid. SE crawlers understand your website better if a website is XHTML valid. To make sure that a website is XHTML valid one would use http://validator.w3.org validator.
A problem arises when you need to check fifty or a hundred pages. For that particular reason I wrote a yet another extremely simple tool to validate lists of URL’s. It uses the same w3.org validator by opening the URL and searching for a phrase “page is valid”. You can check out my XHTML validator online or you can download the source code of HTML validator.
Basically all you need is a list of URLs and the validator will tell you which pages are valid and which ones are not. I hope you will find it useful. Let me know what you think by leaving a comment.
22
Free Online SEO Sitemap Crawler Tool
2 Comments | Posted by Žilvinas Šaltys in PHP, SEO, Tools, Web
The company that I work for has a lot to do with SEO, SEM, PPC. There are such a thing as sitemaps and URL lists that are used in SEO for Search Engines to optimize your site easier and better.
We have a lot of sites which have some SEO development going on. To generate these URL lists is not a task for a human being to do and I didn’t want to develop a custom sitemap generator for each of our projects.
I have tried to search for a tool that could generate these URL lists given only a single root URL. It was a while ago so I cannot say that such tools don’t exist. I also like my tools to be simple and easily extended so I developed a tool of my own. It’s a simple crawler that only needs to know the start URL and the base URL and it can find all your URLs in no time. The tool remembers the pages it has already visited. So for example let’s say I wanted to know all my blog URL’s. I just feed the crawler two URLs and wait for the results. The tool also ignores any outside URLs and adds the base URL to relative links.
You can download the crawler or try it out for yourself.
Please read comments below if you are interested why the second input field is needed.